
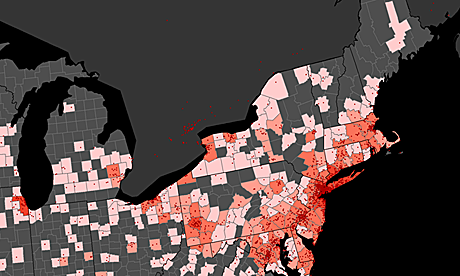
My colleagues Adham Tamer, Ning Wang, Scott Hale and I have been collecting Tweets containing the terms "flood" and "flooding" in order to examine how Twitter usage in the context of Hurricane Sandy might reflect lived experiences. In other words, we are examining the human and social data shadows of an innately physical/material event in order to see what it is that they tell us.
Our initial intent was also to map references to flooding in both English and Spanish in order to explore whether we see significant geographic and linguistic differences in social media reactions to the hurricane. With the rise of crisis mapping and Twitter analysis, we reasoned that it would be important to note any potential differences between English and Spanish speakers (Spanish being a native language to millions of people on the US East Cost).
Second, we see that these data become less useful if we want to draw insights at a finer scale than the county. The data are good at reflecting the broad trajectory of the hurricane, but perhaps less useful for more detailed insights. For instance, it is unclear whether the large number of Tweets that we pick up in New York City, as compared to other places, reflects the scale of devastation to the city or just means that New Yorkers are more apt to Tweet about such an event.
Even more importantly, we only picked up five Spanish-language Tweets over the same period! In other words, it is the absences on this map that are almost more interesting than the mapped results. The lack of published content in Spanish means that we are necessarily only including published content from English speakers in these representations. The absences in the rest of the country are also revealing.
Why exactly are so few people in Kentucky, Missouri, Wisconsin etc. Tweeting about East Coast flooding? Is it because the act of Tweeting about such an event is only really likely to be performed by people in situ, experiencing the storm? Are people outside of the hurricane path simply not that interested in the event? Or should we simply avoid trying to make inferences from Twitter data other than recognising the broad patterns that large events leave on the digital landscape?
Mark Graham's research focuses on Internet and information geographies at the Oxford Internet Institute, and the overlaps between ICTs and economic development. He is also one of the creators of the Floating Sheep blog
More data
More data journalism and data visualisations from the Guardian
World government data
• Search the world's government data with our gateway
Development and aid data
• Search the world's global development data with our gateway
Can you do something with this data?
• Flickr Please post your visualisations and mash-ups on our Flickr group
• Contact us at data@guardian.co.uk
• Get the A-Z of data
• More at the Datastore directory
• Follow us on Twitter
• Like us on Facebook
